Recently at work we were building a system that needed to handle events coming from an upstream system with the capability for high burst throughput (e.g. going from zero messages to one million within a few seconds). The code itself was a good candidate for a Lambda, and the events we needed to listen to would be coming from an SNS topic. Conveniently, AWS offers a direct integration between SNS and Lambda so that you can process SNS messages in a Lambda without any additional infrastructure whatsoever. Sounds great, right?
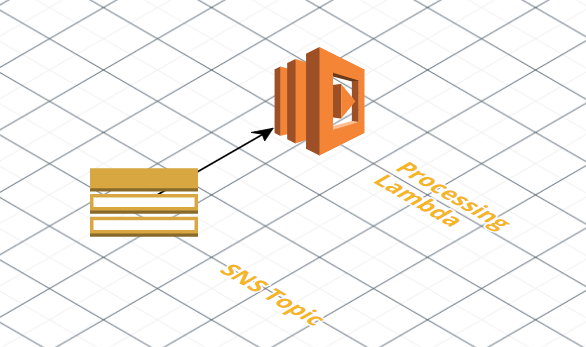
However, every system must have its limits, and the AWS documentation doesn’t always make it perfectly clear how their integrations will react when placed under heavy load. Hence, we really needed an answer to the following question:
How many simultaneous messages can we pump straight from SNS into Lambda before it will start failing to process them?
After a series of tests run during development of our system, we can now answer this ourselves!
The short answer: once the amount of messages going through SNS surpasses the concurrency limit of your Lambda (e.g. 1000), some messages will start failing to deliver and instead get sent to the Lambda’s Dead Letter Queue (if there is one). At this point, a queue (via SQS) is probably more appropriate for your needs.
The long answer: read on for our process of testing and the results before/after introducing a queue into the system!
The Test Setup
To run our load test, essentially all we had to do was start pumping large amounts of messages into SNS via code. Our approach was to just write a C# program to concurrently send X copies of a message into SNS as fast as it could using Task.WhenAll. The code is here if you’re interested, though you could definitely accomplish the same in your language of choice since we’re really not doing anything special to make it work.
We ran our tests in factors of 10, noting down how messages were successful/unsuccessful for each test.
Testing the default SNS/Lambda integration
We had some ideas of what to expect from the default integration thanks to the AWS documentation, but we weren’t sure how they would hold up in practice. Specifically, for asynchronous Lambda event sources (such as SNS) the AWS documentation states:
Asynchronous events are queued before being used to invoke the Lambda function. If AWS Lambda is unable to fully process the event, it will automatically retry the invocation twice, with delays between retries. If you have specified a Dead Letter Queue for your function, then the failed event is sent to the specified Amazon SQS queue or Amazon SNS topic.
This to me suggests that AWS performs some kind of queueing under the covers in order to make sure your Lambda can process all incoming events without them being instantly lost because they couldn’t be processed. However, because the delay between retries is not specified, it’s unclear just how much time is allowed before the event will be discarded. Hence we couldn’t tell without proper testing whether or not this would be sufficient for our needs.
-
10 messages: all successfully processed.
-
100 messages: all successfully processed.
-
1,000 messages: only ~90% of messages successfully processed. Remaining messages were sent straight to the Lambda’s Dead Letter Queue.
Although we could have continued testing with larger batches, as soon as we saw the results from our 1000-message test, we knew this solution was not going to be right for us. Despite our messages being quite fast to process individually, as soon as we hit our Lambda’s concurrency limit (which was around 800 at the time) it was unable to get through all the messages before they were sent to the Dead Letter Queue. We could retrieve those messages and re-process them, but this would be highly undesirable in a production where we’d expect the system to be as hands-off as possible.
Now that it was clear that the default SNS/Lambda integration was not suitable for us, we wanted to test out an alternative solution with an additional SQS queue sitting between SNS and the Lambda.
Testing out SNS -> SQS -> Lambda
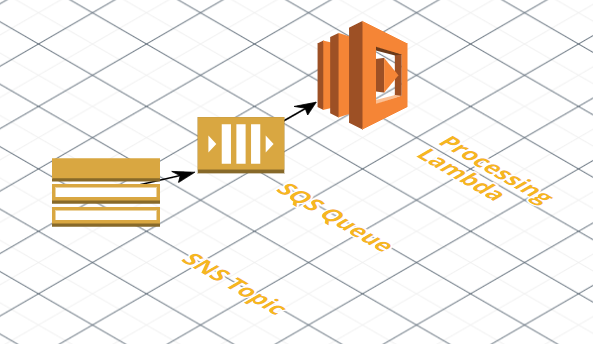
Updating our architecture to include a queue between SNS and our Lambda was fairly straightforward thanks to AWS’s tight integrations between them. Rather than setting our SNS topic as the event source for our Lambda, instead we create a new queue which is subscribed to the SNS topic we want, and then set Lambda’s event source to be our new queue. Since Lambda handles SQS messages in batches (as opposed to one invocation per SNS message), we did need to update our code to handle batches of messages, but the underlying code remained identical.
With that set up, we could restart our testing using the exact same approach as before:
-
10 messages: all successfully processed
-
100 messages: all successfully processed
-
1,000 messages: all successfully processed
Hooray! We’ve surpassed the limits we faced using purely SNS. But now we’re interested not only in how many messages it can process, but also how long it takes to process them, with 1000 messages having taken about 20 seconds to clear through the system.
-
10,000 messages: all successfully processed (took ~30 seconds)
-
100,000 messages: all successfully processed (took ~90 seconds)
Things were looking really great at this point, but I had to take it just one step further!
- 1,000,000 messages: 99.99% successfully processed (took ~35 minutes)
As soon as I bumped up to the one million mark, we did start to see some errors - however, these weren’t errors because of the SQS/Lambda integration, rather of our system itself! At this high level of throughput, we started exhausting our database, which slowed down the system a lot and resulting in some failed messages. Despite all that, we still only saw a failure rate of 0.01%, which I was quite impressed with!
At this point, it was obvious that utilising SQS was the correct solution for our system. With some additional tweaks to the rest of our system - such as reducing our Lambda’s concurrency limit to 100 so as not to overwhelm our database under load - we were also able to eliminate any errors occurring during the one million test, and reduce the total processing to around 15 minutes.
Conclusions
Just to re-iterate our lesson here as a key takeway:
If you’re building a high-throughput system with SNS and Lambda, don’t rely on delivering straight from SNS into Lambda. Adding a queue in the middle will ensure that large bursts of messages don’t get discarded once you hit Lambda’s concurrency limit.
Thanks for reading! If this has been helpful, consider following me over on Twitter. It’d be great to share more with you in the future!